GEMV 코어¶
GEMV 코어는 LLM 자기회귀 디코딩(Autoregressive Decoding) 단계의 지배적 연산인 행렬 × 벡터(``y = W x``)를 담당한다. 배치 1 · 시퀀스 1의 디코딩에서는 전체 FLOPs의 85 ~ 98% 이상이 GEMV이므로, GEMV 처리량이 초당 토큰 생성률(TPS)에 직접 비례한다.
중요
2차원 시스톨릭 어레이 하나만으로 디코딩을 수행하면 유효 가동률이
1 / 32 (= 단일 행만 활성)까지 떨어진다. pccx v002는 이를 해결하기
위해 GEMV 전용 1D 벡터 코어를 GEMM과 병렬로 두고, 두 경로가 동일
L2 Cache를 공유하는 이기종(heterogeneous) 구조를 채택했다.
1. 연산 대상¶
GEMV의 입력은 길이 N의 액티베이션 벡터와 N × N 크기의 가중치 행렬이다.
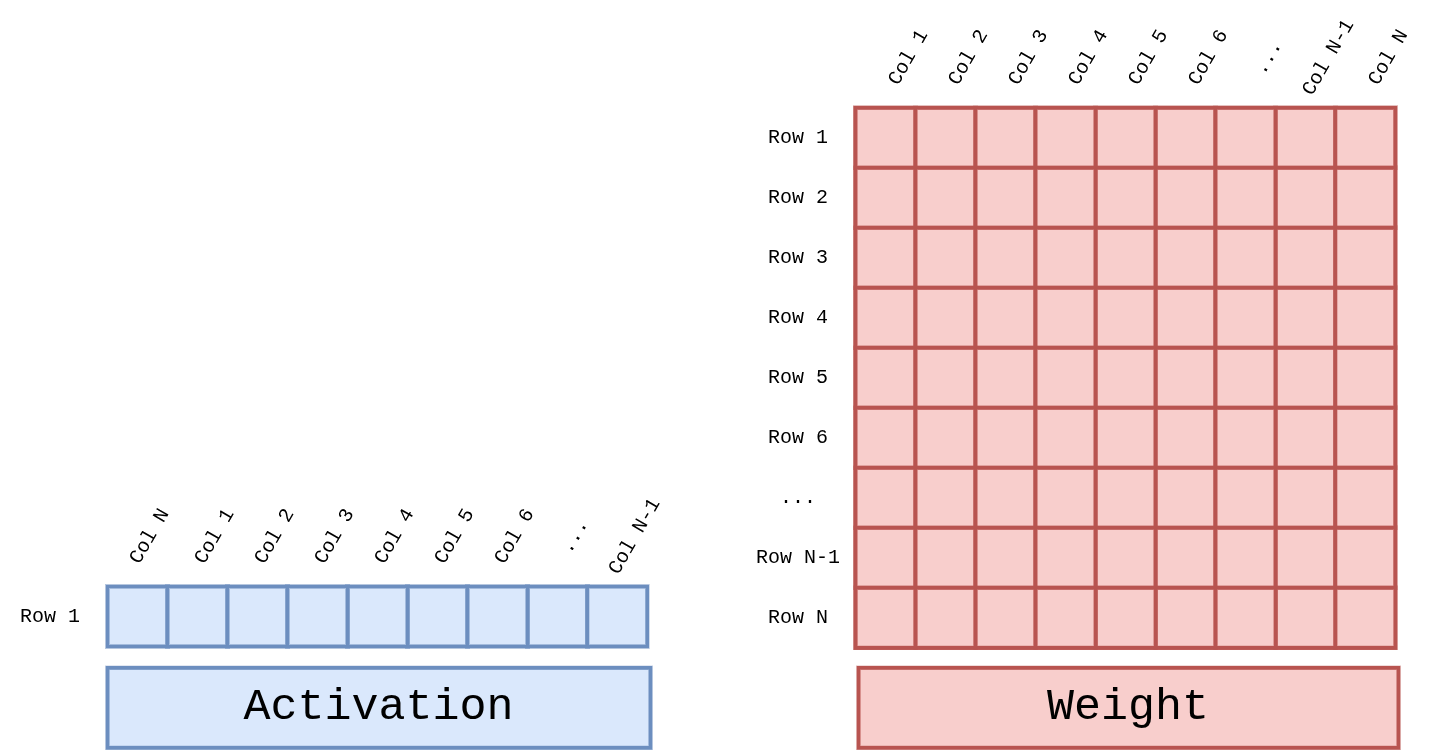
그림 10 Figure GEMV-Operands. Activation은 1 × N 행 벡터, Weight는
N × N 행렬이며 두 피연산자의 내적 결과가 새 길이 N의 출력 벡터를
구성한다. Attention의 Q·Kᵀ, FFN의 projection에 모두 동일한
형태가 적용된다.¶
2. 구성¶
파라미터 |
값 |
|---|---|
코어 당 차원 |
32 (K) × 1 (M) |
코어 개수 |
총 4 개 ( |
코어 당 곱셈 폭 |
32 MAC / clk (INT4 × BF16, LUT 기반 사전 계산) |
Stage 1 누적 DSP |
16 DSP48E2 · 코어당 (32 부분합 → 16 이중합) |
Reduction 트리 |
5 단계 (32 → 16 → 8 → 4 → 2 → 1) |
피크 처리량 |
32 MAC × 4 코어 × 400 MHz = 51.2 GMAC/s |
3. 코어 내부 구조¶
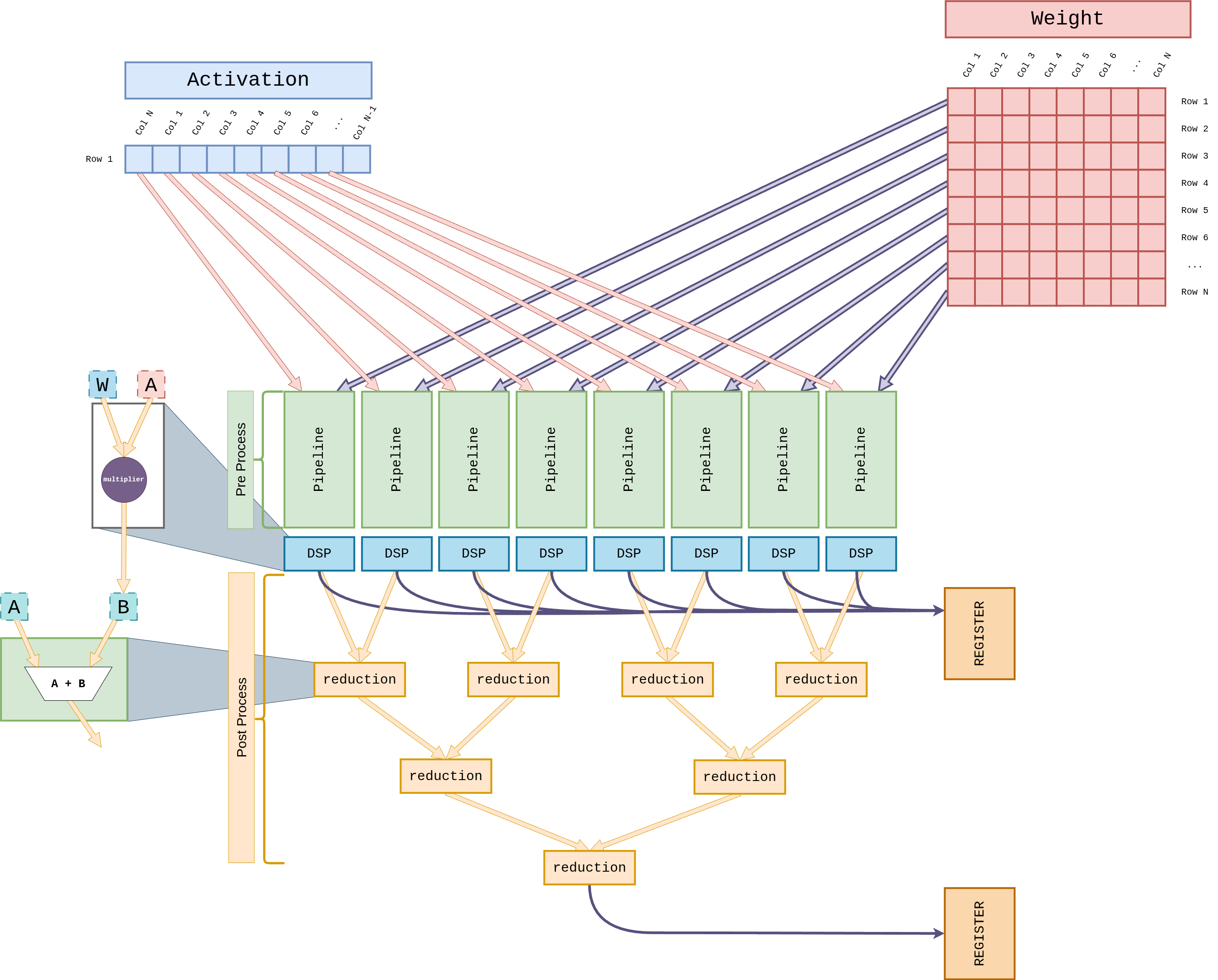
그림 11 Figure GEMV-Core. Activation 1행과 Weight 1열을 Pre-Process 블록에서 dequantize하여, 32개 LUT 기반 곱셈기가 (W × A)를 단일 사이클에 병렬 수행한다. 32개의 부분곱은 5단계 reduction adder tree(Stage 1: DSP48E2 16 슬라이스, Stage 2–5: LUT)를 거쳐 스칼라로 축약되며, Post-Process 블록에서 스케일·bias를 적용한 뒤 REGISTER에 기록된다.¶
3.1 Weight Streaming¶
디코딩 단계에서는 각 레이어 가중치가 매 토큰마다 한 번만 사용되어 재사용이 없다. 따라서 GEMV는 GEMM과 달리 Weight Streaming 전략을 적용한다.
HP2/HP3 포트에서 가중치를 연속 스트리밍.
Weight Buffer 를 경유해 각 코어의 W-side Pre-Process 에 직접 주입.
가중치 재사용이 없으므로 버퍼는 순환 FIFO 형태로만 동작.
3.2 Activation 재사용¶
액티베이션 벡터 x는 L2 Cache에 상주하며, 여러 GEMV 코어가 동일한
벡터를 브로드캐스트해 소비한다.
L2 → L1 Cache 로 액티베이션 타일 프리로드.
Pre-Process 블록이 INT8 → BF16 dequantize 와 scale 수행.
32 개의 LUT 기반 곱셈 유닛이
(W × A)를 한 클럭에 병렬 실행. (W 가 INT4 이므로 가능한 16 개 가중치 값에 대한 곱을 먼저 LUT 로 사전 계산한 뒤, 실제 W 비트 패턴으로 선택만 수행.)
3.3 Reduction Tree¶
코어 당 32개의 부분곱을 아래 5단계 트리로 스칼라 한 개까지 축약하며, 각 단계마다 파이프라인 레지스터를 삽입해 400 MHz 타이밍을 확보한다.
flowchart TB
MAC["32 × partial products<br/>(LUT-based W × A)"]
--> S1["Stage 1 — DSP48E2<br/>16 × (a + b)<br/>32 → 16"]
S1 --> S2["Stage 2 — LUT<br/>16 → 8"]
S2 --> S3["Stage 3 — LUT<br/>8 → 4"]
S3 --> S4["Stage 4 — LUT<br/>4 → 2"]
S4 --> S5["Stage 5 — LUT<br/>2 → 1"]
S5 --> OUT[/Scalar/]
Stage 1 은 DSP48E2 의 A:B + C (ONE48) 모드를 써서 인접한 두
부분곱을 더하는 용도로만 사용 (16 개 DSP 슬라이스 / 코어). Stage 2–5
는 LUT 기반 가산기로 구현되어 DSP 예산을 절약. 구현 파일은 v001 의
GEMV_reduction.sv · GEMV_reduction_branch.sv 를 그대로 계승.
3.4 누적 & 포스트프로세싱¶
Reduction 결과는 Result Accumulator에 저장되어, 다음 가중치 열과 순차적으로 합산되어 행 전체의 부분합을 완성한다.
Post-Process 에서 weight-scale / activation-scale / bias 를 적용.
최종 INT8 재양자화 결과를 L2 Cache 또는 SFU 직결 FIFO 로 전송.
4. 병렬화 전략¶
4개의 GEMV 코어는 두 가지 병렬화 모드를 지원한다. ISA의
parallel_lane (5-bit) 필드로 활성 코어 수와 파티션 방향이 지정된다.
모드 |
설명 |
|---|---|
Row Parallelism |
출력 벡터의 서로 다른 행을 4 개 코어가 분할 계산. 가중치 행렬이 row 방향으로 스트라이프 됨. 액티베이션은 공유. |
Head Parallelism |
Multi-Head Attention 의 서로 다른 헤드를 4 개 코어가 독립 처리. 액티베이션(Q)·가중치가 헤드 축으로 분할됨. |
5. 내장 Lookup Table¶
GEMV 코어는 W4 dequantize와 MAC을 하나의 LUT 사전 연산으로 병합한다.
GEMV_generate_lut.sv(v001 계승) 가 BF16 액티베이션A1 개와 INT4 가중치의 가능한 16 개 값 (-8 ~ +7) 에 대해 16 개 사전 계산된 곱A × w를 만든다.이를 32 개의 액티베이션 위치에 대해 병렬 생성하므로, 코어 당 32 × 16 = 512 개의 사전 곱 이 매 클럭 준비된다.
실제 가중치가 도착하면 4-bit 패턴을 인덱스로 LUT 에서 단순 선택 → MAC 한 번에 해당하는 값이 Stage 1 누적 DSP 로 바로 흘러간다.
스케일 계수는 Constant Cache 에서 인덱싱.
6. Softmax / Normalize 와의 연동¶
GEMV 출력은 주로 아래 두 패턴으로 소비된다.
Attention:
Q·Kᵀ→CVO_EXP/REDUCE_SUM(SFU) →V·softmax(다시 GEMV)FFN Projection: GEMV →
CVO_GELU/CVO_SCALE(SFU) → 다음 GEMV
GEMV ↔ SFU 경로는 L2 Cache를 경유하지 않고 직결 FIFO로 연결되어 왕복 레이턴시를 제거한다. 자세한 내용은 SFU 코어 (Complex Vector Operations)를 참조한다.